Well I’m glad to see you guys have done all the work of writing my ideas out for me haha. Especially in the light of flakehub and a small team I agree distributed is necessary.
In the nix Discourse I have a few long posts about how we can integrate distributed and monorepo nicely, and basically go at our own pace.
(I dont mean to skip over your idea @jakehamilton, I’ll just have to respond on that another time since this post of mine is mostly copy paste for me)
The idea is simple, packages have one job; update themself as fast as possible on their own repo get their test suite passing using whatever dependencies they want. Ideally depending on a tagged monorepo release like 23.11. Not much to explain.
On the other hand, the monorepo has a much harder job, but still just one job; get an “all green” bundle of packages. Meaning, every package has its inputs overridden to use monorepo inputs instead of whatever pinned-input was used by the individual package repo. E.g. python (depending on nixpkg23-11.glibc) gets changed to python depending on self.glibc, and we want all the tests to keep passing.
Let’s say we start with an old but “all green” monorepo.
What do we do?
Let’s start, what I call, major waves. Every major and minor wave is its own git branch. So actually let’s start two major waves because we can do waves in parallel.
WIP-Wave1.1: we update the glibc of the monorepo to idk, glib latest-2
WIP-Wave2.1: we update the glibc of the monorepo to glibc latest -1
Well everything is broken now (probably). So we stay on WIP-Wave1.1 making whatever changes to downstream packages, like updating python to 3.11, to get them working with the new glibc. Whatever it takes to get tests passing, including marking some packages as broken. As soon as all the tests pass, we have reached an “all green” status. We can rename from WIP-Wave1.1 to just “Wave1.1”. At the same time we do the same thing on wave2.1.
The first minor wave is the most difficult because “test downstream” means “test EVERYTHING”. On the second minor wave WIP-Wave1.2, and WIP-Wave2.2, we update something “below” glibc, like llvm. That breaks everything again, we fix them all again and repeat. I say glibc and llvm because pretty much everything depends on them, they’re at the root. For example, numpy depends on python depends on llvm depends on glibc. The minor waves go in reverse order. Ex: the minor wave updates python, and fixes everything below python. The next minor wave tries to update numpy, and to fixes everything below numby.
The monorepo is never going to have the latest versions because it takes forever to test stuff. But that’s okay because if you want the latest version, just pull it down from the individual package flake on flakehub.
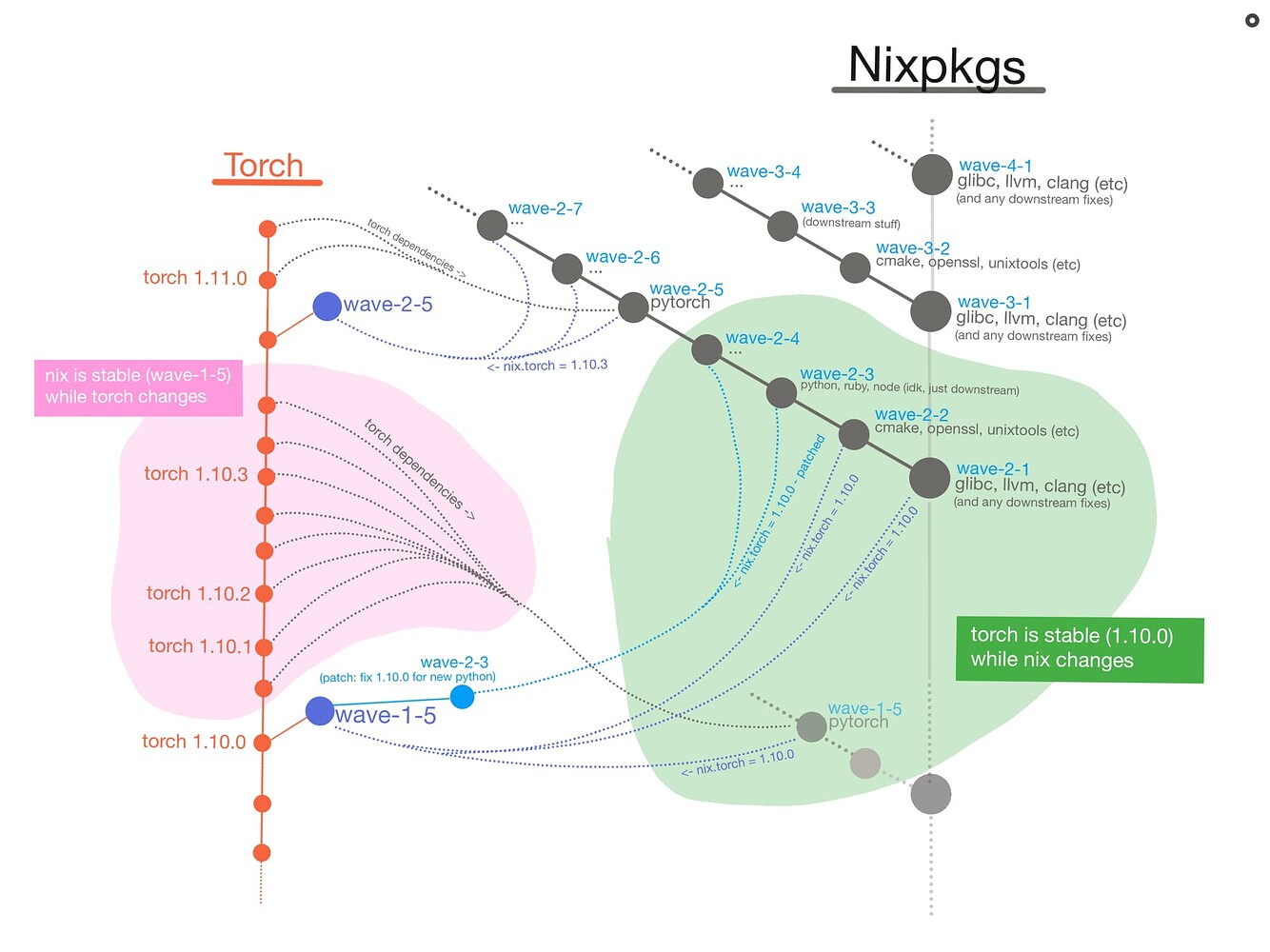
Using pytorch as an example package, and nixpkgs as the monorepo. This is what their commits (dots) might look like. Arrows means dependency.
My initial thoughs are; probably a lot of work to do this straight up, so maybe try just making any kind of monorepo first and eventually get to this system. Either that or we start with this system with a subset of packages (80/20 rule) to limit complexity and compute.
Also maybe @jakehamilton 's
grouping idea could be nicely combined with this approach.