At some point in this thread I tried to summarize the goals we want to achieve with the multi-repo approach. Regarding goals from the user perspective, this was:
Therefore the answer to
but why can’t the multiple repos just be an implementation detail?
is: because we see (or: saw at some point in the discussion) value in exposing this implementation detail to users.
I do agree though, that for users of the top-level / auxpkgs this multi-repo architecture should just be an invisible implementation detail.
I agree, but am concerned we are getting stuck in the weeds with all of the talk of resolving circular dependencies, what repos can depend on other repos, etc.
There’s nothing to say a user can’t input a single repo, or a small subset like core and python if that’s all they care about. But there might be value in ending the complexity there. As soon as you want to use a package that crosses repos, you are in auxpkgs territory. Pulling strictly from, say, the python repo wouldn’t make available any packages that depend on other repos, you’d need auxpkgs for that.
Okay finally a full response for you @liketechnik (and I think this will help others too)
So imagine two pictures 1. A spider web 2. A tree (a normal/hierarchical tree)
Right now nixpkg’s control flow is like a spiderweb, any piece of code is allowed to call/depend anything else at any time, including itself.
The proposed repo structure (e.g the registry) allows (but doesn’t enforce) de-tangling the spider web.
Those two rules, at least partially, enforce turning the spider web into a hierarchical tree.
Without those rules (or better rules) we would more than likely start making our own custom spiderweb.
I agree we should be cautious about automating things. This automation is for one file, and the only thing that is automated is the order of the attributes. It is effectively a sort function. No advanced logic or “intelligent” dependency detection.
sig_sources and flakehub packages will say (or be annotated to say) “this X derivation depends on A,B, and C” (it’ll do this inside of json/toml or a yet-to-be-determined structured way)
the automated system says “okay, I’ll make sure X appears below A,B, and C.” (And report an error if that is impossible because of circular dependencies)
That’s the only automated thing.
Doing the sorting by hand would be extremely time consuming and error prone considering multiple people editing upstream and downstream sources.
Thanks for echoing those. I think that’s the best way to identify confusion.
core: (some room for discussion, but nbd)
sig sources:
registry: No, the registry doesn’t import ecosystem(s). If sig_repos were analogous to fishing, lumber, and mining organizations, then the registry would be an assembly line, and ecosystems would be the big-box retail stores and restaurants (lumber → assembly line → retail store, never the reverse order). I would also go as far as saying it’s not clever at all. It’s the most boring un-clever way possible to organize packages; a flat list in (effectively) chronological build order. Converting the highly-clever recursive categorically-grouped nested nixpkgs structure into the most dumb flat structure ever is what is really hard.
ecosystems: doesn’t have derivation definitions. It exposes user-facing nix functions and it points to derivation definitions stored in the registry. If the user-facing nix function is ONLY user facing, it can be defined in ecosystem. If a function is used by maintainers to build packages and also happens to be user facing, then it needs to go in sig_sources and merely be imported into ecosystem.
the aux namespace repo: will be like 3 files and ~20 lines of nix code possibly forever. “Update the flake lock and commit” will be its whole workflow. Ideally users use this endpoint and know nothing about the other repos. If they want lib, use aux.lib instead of pulling directly from the lib repo.
polypkgs: while “tie everything together” is not necessarily wrong, it is probably misleading. Polypkgs is a drop-in replacement for nixpkgs, but we want to use polypkgs as little as possible. Sadly “as little as possible” is probably still going to mean “all over the place for everything” at first but oh well. However, unlike the aux repo, polypkgs is going to need a notable amount of nix code. At first it will be simple, but as we overlay more and more things it is likely to grow. Sometimes overrides need extra logic to work correctly.
Think of it like this: we deprecate a function in the internal lib, and we do a quick search to see if that deprecated function name exists in any aux repo. If the answer is no, we can safely remove the deprecated function from the internal lib. Nice and clean. With the public lib we can never ever ever ever remove/rename a function because it could break an unknown number of other peoples nix code (which is supposed to not bitrot). We see this already with deprecated junk like toPath in nix. We can’t move very fast when changing lib because every mistake is a permanent mistake. For the internal lib we could move a little faster knowing there is room to fix our mess/mistakes later.
Sorry if my mention of home manager and dev tooling was confusing. They were supposed to be examples to explain the intuition.
Key idea: all packages (derivations) are fully defined before ecosystem even begins. If it has to do with packages then it should be handled in SIG sources, flakehub (e.g. external), or registry (and of course core packages will be handled in core).
Is [dev env] something that needs to be kept together with packaing (for technical/maintenance reasons)?
In practice, I don’t know! We will have to try and see. If it doesn’t get used for packaging, then it can stay in ecosystem. If it does get used for packaging (or if the maintenance team simply finds it helpful) then most of the code will live in sig_sources, then ecosystem will just reference it.
why focus on nix cli for core?
TLDR: it’s a well defined starting point. Its not a must have. We can talk about it more later.
I’m a bit confused on what this part is saying. My understanding is
We need polypkgs internally while we bootstrap
The easiest way for us to test aux will be to start swapping out nixpkgs with polypkgs in our own projects
Other people might like our maintenance. For example, if we fix/maintain an unmaintained package on nixpkgs, then others might use ploypkgs to get that fix and (inadvertently) help us out my testing our code and maybe even contributing.
Yes and no. Using packages from different sources can (and does, I’ve tried it) cause conflicting dependencies leading to failed builds. For example: package A from Core and package B from nixpkgs. A and B both depend on C. Package D depends on A and B. The build for package D will fail because there is a disagreement on what version of package C to use. So using it as a source of extra packages is fine, but as a dependency on an aux package may cause issues.
Yes, that is very much the idea. At least thats what I had in mind.
Nixpkgs philosophy was basically/accidentally “if it works, it works”. One circular dependency isnt that bad. Two isnt that bad. Maybe even three. But how can you deny the fourth PR for a circular dependency but not the 3rd one? It would feel like mistreatment to the person making the PR (and plus “the PR works and is something important”). That kind of “one more” approach is exactly how we end up with a mountain of tech debt so massive, like nixpkgs, that we effectively we hit “tech debt bankruptcy” – the point where people would rather try starting from scratch (or nearly scratch) than fix the original. People practically need a PhD in nix just to have a “big picture” understanding of the control flow of nixpkgs for building cowsay. And it’s precisely because of circular dependencies and lack of standards.
So I want to be clear, this issue isn’t like a footnote or “clean for the sake of being clean”. This is the meat and potatoes of why some of us are here; Nixpkgs has long failed to address the unmaintainablity crisis and we want to start paying down the mountain of tech debt nixpkgs has created.
We are in agreement. I usually have no less than 4 pinned nixpkgs versions in the same project ranging from 2018 to 2024 so I regularly deal with mixture problems. In particular the mismatched dynamic library problems.
That said I don’t really understand why that would affect aux needing/not-needing polypkgs. I don’t think aux can be used to build anything practical anytime soon without depending on nixpkgs and gradually overlaying parts of it. Did you mean to highlight the bullet point about other people pulling in a fix from polypkgs?
This seems like a really well thought-out design. Is there currently any work towards formalising / implementing it? If not, I think it would be helpful to put this in a github repo or something so that we can have more organised discussion around it (similar to an RFC, but not really).
The point I was trying to get at is that I believe using nixpkgs as a crutch while building out our own package set is not a great idea. For end users to use both is fine, but I think we can work to slowly package everything in our own manner independent from nixpkgs at the start rather than overlaying it (also tried some stuff with overlaying and got caught in infinite recursion ).
I’m working on implementing an independent core set of packages here: add stdenv by vlinkz · Pull Request #2 · auxolotl/core · GitHub. It definitely takes inspiration from nixpkgs-skeleton, but rather than forking and removing, I’m taking bits and pieces necessary for a successful build. @Jeff I would really appreciate if you could take a look and provide any feedback.
That is the best part, we can get started on lib and core while continuing the discussion since lib and core don’t need to touch the not-formalized sig_sources/registry/ecosystem.
Awesome!
Successful build of what? nix-cli?
Hey, I mean if you’re capable of “eating the elephant” in one bite and just straight up get a from-scratch core working thats awesome. I don’t think I’m capable of that, at least not with the time available to me.
I’d be happy to! There is just one thing…
Getting Started Blocker
I would be happy to start contributing to the lib and core stuff, but the future of aux licensing is somewhat of a blocker for me. I mean lib and core are independent so as long as they are MIT/similar I can start working on them, but beyond that I don’t think I can contribute code to sig_sources/registry until I know if the aux system is going to end up as copy-left or some gray-area that makes bussinesses avoid it.
I’m afraid, but I’m still struggling a little to correctly get a mental image of this.
If you don’t mind, I’d like to try to understand these better with your help again, but I can also totally understand if you’d rather focus on the actual technical aspects of this with people who are already more experienced with how nixpkgs currently works and how your proposal would therefore play out.
Based on your explanations, let me try to echo my updated view on those again (leaving out lib, core since we both have the same understanding of those already):
sig sources:
imports: core, lib
provides:
bootstrap of SIG/language toolchains, e.g. the python compiler, nodejs or the rust compiler
SIG/language nix functions for creating packages, e.g. today’s buildRustPackage, buildPythonPackage or buildNpmPackage
packages of SIGs/languages, e.g. today’s pythonPackages.sphinx, nodePackages.prettier, but not yet actually build-able, since the “connection” with the dependency derivations happens in the registry (?, see also below “registry->provides”)
registry:
imports: core, lib, sig sources
provides:
flat structure of package derivations defined in sig sources (+ core?), i.e. it “connects” the derivations (today’s callPackage?)
ecosystems:
imports: registry, lib
provides:
exports of the package derivations from the registry, e.g. today’s pythonPackages.sphinx, nodePackages.prettier
exports of the SIG/language nix functions for creating packages, e.g. today’s buildRustPackage, buildPythonPackage or buildNpmPackage
ecosystem specific nix functionality that is not used for creating package derivations - here I have a hard time coming up with actual examples - is this e.g. the nixos configuration module system?
aux namespace repo:
imports: ecosystems, lib
provides:
exports of ecosystem + lib
polypkgs: (temporary?) nixpkgs + aux combination, that allows us to lean on nixpkgs for getting things started and then progressively replace nixpkgs content with aux content
Regardless of the details of the individual repos I’m trying to understand above:
From your explanation I gather:
we do end up with multiple repos
we do not end up with SIG specific repos, that is e.g. both rust and python infrastructure ends up in the same “sig sources” repo
we do end up with packaging infrastructure concern specific repos, that is we have cleanly separated library (‘lib’, i.e. derivation-less functions), core (‘core’, bootstrapping compiling anything at all), derivation definitions (‘sig sources’, language specific bootstrapping/derivation helpers, all packages), derivation combination/connection (‘registry’), module defintions? (‘ecosystems’) + the one-thing-for-all repo(s) (aux, polypkgs)
Is that understanding correct? Or are, e.g. sig sources or ecosystems, mean to be split-able into multiple SIG specific repos?
I think you’ve got it! Including especially the part like this:
Correct, a sig source wouldnt import it (like nix import). The sig source would just provide a function with [pkg] as an argument. This is how we can prevent python SIG importing a JavaScript SIG and then later the JavaScript SIG import the python Sig. Both defer the import and the registry connects them later.
I think the registry can be seen as an alternate design that avoids the need for callPackge. Instead of fixed point recursion and dumping all arguments/nixpkgs into the builder function (e.g. the callPackage approach), we can just call the function with an explicit list of correct arguments. Unlike nixpkgs we will statically know the inputs for each builder function. For exmple, the top level registry could have the arguments of every package function be { lib = lib; core = core; inputs = { /* explicit list of dependencies */ }; polypkgs = polypkgs; }.
So other than that last point about clean separation, I actually dont care much about what is a repo or not. For example, sig_sources could be one or many repos and I don’t think it would matter from the design perspective.
Same goes for flakehub stuff. We could have a generic sig_source which has a wrapper/adapter for each flakehub import. Or the wrapper/adapter could be in registry, and just be the not-automated part of the registry. Either way is fine as far as I can tell.
From my view tarball stuff and git-history stuff is more of a reason for potential grouping/separating of repos, and honestly I think theres arguments on both sides. We could have one giant repo with sig_sources and registry as folders or the opposite with the python sig_source having its own repo.
For the tarball and flake reasons polypkgs would need to be a separate repo. But I think thats it.
I think I get the design, thanks for taking the time to explain it ! I’m not 100% sold on it though, but I think the key idea that we should keep no matter what is splitting package definitions and dependency resolution (I’m not sure that’s the right way of formulating it, but basically the last post from liketechnik).
Something I’d like to try is leveraging the module system (or something close to it if not the current nixos module system) to define derivations. There was an early design that Eelco Dolstra presented here. I don’t like at least half the ideas in this talk, and I don’t want to implement something that would look like that for aux (I’m more citing as a reference). But the core concept appeals to me and I believe could be a better approach than overlays and overrides. I think it could also fit or even help with jeff’s design.
There’s one thing I’m not sure I understand with the design though (about registry):
And in the multi-version packages topic, you said:
I want to mention pkgs.${pkgName}.versions."v${version}" will work fine in ecosystem, but registry can’t have that format while keeping all the mentioned benefits. For discoverability/automation every derivation in registry needs to be only 1 attribute deep.
I’m not sure I understand 100% why this is required, and if this is going to be an issue with multi-output derivations ? E.g. someCLib.dev.
Yes, the module system idea looks very intriguing!
That reminds me that I wanted to bring up the topic of overriding (in the sense that: As a user of aux, I am able to change how a package, no matter how deep in the dependency tree it is, is build) packages in general, because: if the registry contains the ordered packages, how does overriding a package interact with that, e.g. if another dependency is added when overriding (that dependency might cause the overriden package to need to be ordered differently, among other things)?
Possibly building the registry dynamically instead is a solution. On the other hand, that would negatively impact the eval time of the packages if none are overriden. Or this whole point becomes moot regarding ‘leveraging the module system’.
Mhm, maybe this is just a thing that’ll be much clearer when we’ve started implementing, so it’s better to leave it for later.
Nope multi-output derivations should be fine. AFAIK all the outputs can always be at the same point in the dependency tree. For example, I don’t think there is a time where someClib.man is needed by otherPkg and then someClib.lib needs otherPkg.
To maybe show that example a bit better with a dependency list
(e.g. perl needs bash, someClib needs perl)
bash
perl
someClib.man
someClib.dev
otherPkg # < this would be a problem, but I don't think its possible
someClib.lib
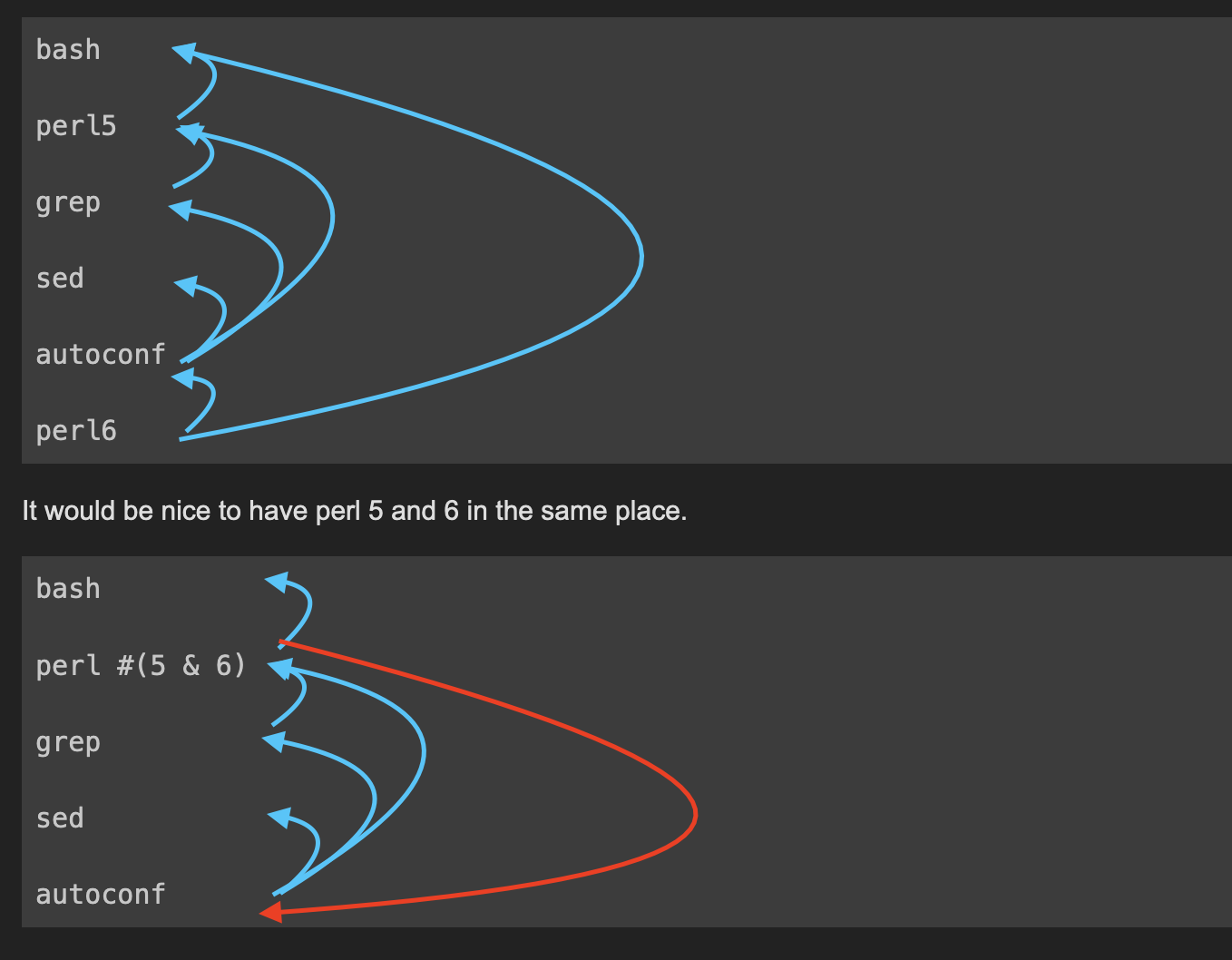
Good question, its because of bootstrapping. If we had multiple versions of a package always defined in the same place (which is what I think the pkgs.${pkgName}.versions."v${version}" effectively requires) then its a problem, because sadly stuff like this happens, where a newer version of a package (like perl6) depends on a tool (like grep) that depends on an older version of the first (like perl5).
I agree, and I think that would be good as a separate topic/thread. Whatever format we pick, I’ll just call it a package for now. The registry doesn’t need to be a list of derivation-objects. The only requirement is each package has a static list of dependencies and a static version (e.g. not a “ask me for a version and I’ll tell you if I can build it” design). If the package-builder function is so flexible that it’s dependencies list isn’t static, then its too flexible for the registry design and there is no way to create a DAG of package dependencies.
I think this is worth discussing even before implementing stuff.
To be a bit more abstract, instead of nixpkgs’s override lets say “configuring” a package, with nixpkg’s override being one way to configure a package. We actually need to define “package” a bit more so I’m going to make a difference here between “tool” and “package”. I’ll say python is a tool, while python 2.7 is a package and python 3.10.5 is a package. My definition is that aux package’s have a static list of dependencies and versions. Meaning python 2.7.0, 2.7.1, 2.7.2, etc could all be “the same package” so long as the list of build and runtime dependencies do not change. A package doesn’t have to use all of its dependencies for every build (ex: a user that picks withCuda=false). A user can also give a package another package as an argument, but I wouldn’t consider that a dependency. E.g. pythonWith [ pythonPackage.numpy ] doesn’t mean “python dynamically depends on numpy”.
For “configuring” a package, that should never be possible. Think of it this way, the user is effectively making a new package that isn’t even in the registry. Everything in the registry is “above” that user configured package, so they’re free to “depend” on anything in the registry.
Overlays
Overlays however, I think we’re going to have to discuss a lot more.
Part of what I really hate about nixpkgs/callPackage is that it effectively mutates top level, to the point that (IMO) it defeats even using functional language. For example, if you want to replace nixpkgs.perl, I could ask “well, which version of nixpkgs.perl? the one used in stage 2 bootstrapping? the one used to build grep? the one used to build the latest gcc?”. Trying to overlay core stuff becomes a nightmare (which I think @VlinkZ hit just recently).
The registry has an obvious advantage because, well, we would explicitly list core.perl and perl_stage1, and perl_stage2. There are also no nested packages, so overlaying numpy is the same as overlaying any other thing.
But there’s still challenges
Could an overlay of a package change its order in the dependency tree?
Yes, but its not a structure-breaking issue. Nix is still lazy. The worst possible scenario is behaving likenixpkgs; nix dynamically figures out the new tree and the package still builds (or the overlay wasn’t done correctly and it causes infinite recursion). The total ordering is for the sanity of maintainers. Overlays are mostly beyond that relm (I’ll get to internally-used overlays in a bit).
That doesn’t mean overlays with the registry are user-friendly. I mean overlays are kind of a nuclear option with no warning label, and people use them for stuff like, just adding more packages to nixpkgs (without actually replacing any existing stuff). We should probably think about different usecases.
Extending what packages exist (additive only)
Just surface-level replacement, no cascading effects.
E.g. if python used auxpkgs.perl (perl6), then it the user does a surface level replacement, python still would build with the original auxpkgs.perl (perl6) even if auxpkgs.perl was now, idk, perl7 or somehting.
Simple targeted replacement.
Lets say numpy and python have a nested dependency on gcc. Meaning gcc is not a direct dependency, and not an argument to their package function/module. Its realistic that we want to replace the gcc that is used for both python and numpy “all the way down”, but not replace the gcc for everything (e.g. triggering a build-from-scratch for stuff like coreutils). It would be a pain to find every tool in the numpy/python dependency tree and manually configure the gcc argument for all of them. Ex:
Same as above (change gcc for only numpy and python) but not “all the way down”. For example, if numpy used coreutils, and we just wanted to call a coreutil binary at build time without rebuilding coreutils using the new gcc. While this is pretty challenging, I think there is a good way we can help with this.
Deep everywhere replacement.
This is last usecase that is obvious to me; the cascading changes. Stuff like nixGL patching a bunch of tools, or using an overlay to apply a security fix for a zero-day vulnerability, even if it means rebuilding a ton of stuff. IMO this is the time where the “nuclear power” of overlays is necessary.
I don’t think we should ever do this kind of overlay inside of aux (including for any ecosystem) but I do think it should be an option to users, even if it requires advanced knowldge to do without breaking everything.
I think we can make these user-friendly (at least as much as is possible) with the registry design.
Nix lang itself should be able to handle extensions and surface level replacements (ex: auxpkgs // { newThing = 10; })
The registry should be able to handle the deep everywhere replacement by having top-level be a function that accepts replacements as an argument.
# top level
{ self, deepReplacements }:
let
...
python = (
if (builtins.hasAttr "python" deepReplacements) then
(deepReplacements."python" {
lib=lib;
core=core;
inputs=self; # < allows for recursion
polypkgs=polypkgs;
})
else
# whatever a normal package looks like
builtins.import ./sig_repos/python/pkgs/python.nix {
lib=lib;
core=core;
inputs={
input1=self.input1;
input2=self.input2;
/* etc */
};
polypkgs=polypkgs;
}
);
We can also potentially compute the new location of a package in the package tree at runtime and tell the user about weird recursive stuff, or warn about how many rebuilds this is going to cause/what downstream packages will be affected by the change.
The other cases, the targeted replacements, I think is actually more of a dicussion for that “what is a package” thread (module design). For example, maybe in additon to a static list of dependencies we should statically mark which ones are build dependencies vs runtime dependences. For example, with that numpy/python targeted example, maybe we only wanted to deeply-replace gcc runtime dependencies but not gcc build dependencies. I think the registry design would help, but ultimately tooling would be needed to make overlays user friendly.
I’ve been working on an early proof of concept based on @Jeff’s design over here - had wanted to do a bit more work on it but currently have some life stuff to deal with.
Hopefully it is at least somewhat comprehensible - happy to clarify things when I have time.
This looks fantastic to me! Already having the start of a resolver is impressive!
For this prototyping phase, I think your approach of one repo is good. I’m sure, as we fill in details, like core, that we will have to restructure things. And restructuring is easier when everything is in one repo.
Next tasks:
Start a new/empty pure lib that doesn’t use recursion. Add to it as-needed for core
Without recursion, get the nix CLI built for Linux (because it has way way fewer dependencies than the MacOS nix-cli)