From what I have been told the eval time for legacyPackages is horrible.
I think its less, since each are grouped by clear distinctions. And yes I most certainly want a search.nixos.org replica.
From what I have been told the eval time for legacyPackages is horrible.
I think its less, since each are grouped by clear distinctions. And yes I most certainly want a search.nixos.org replica.
Ah, in that case that makes sense.
I promise I’m not trying to sea-lion, but genuinely don’t understand. I don’t get how grouping the packages helps maintainers, isn’t it net neutral? Like the user has to find it regardless and not interact with the maintainers at all?
Well in theory we can manage permissions around certain repos and files better.
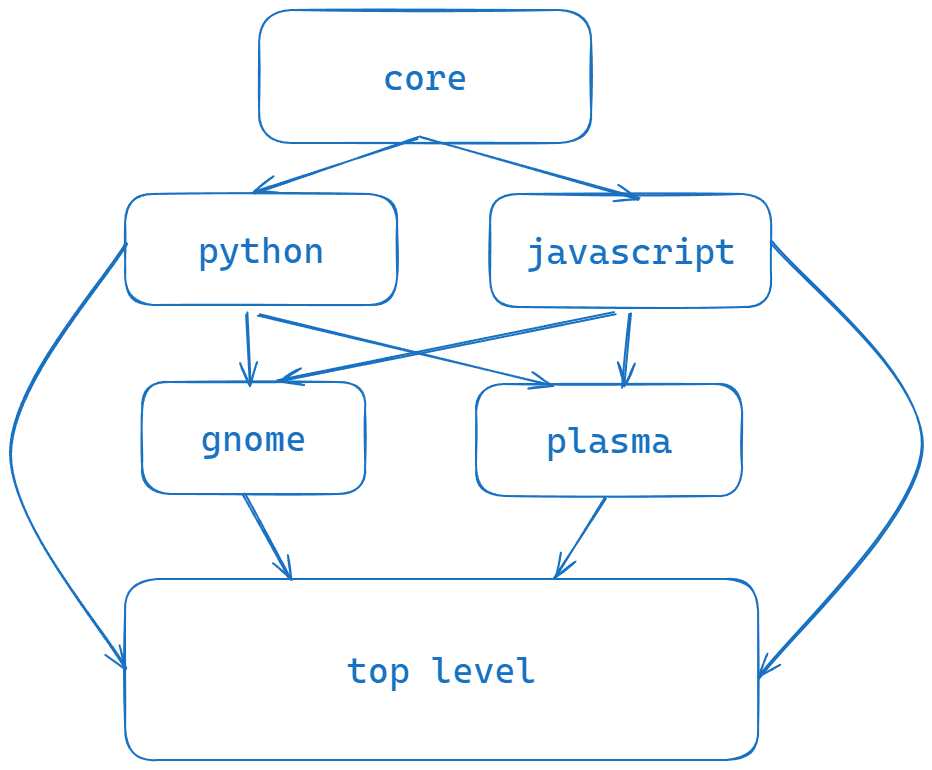
I don’t want to get too technical here. But here we go. Grouping things leads to “doors” in your mind and each time you use said “door” the stronger it gets. So each time a maintainer creates or updates a package they will have the built up the strength of that given “door” and work there. In this case the “doors” are analogous to repos and subsections of each repo. So the maintainers each time they create a PR will get faster and faster, but at a improved rate to the way nixpkgs does it. Why you might be thinking does nixpkgs not have the “by-name” structure. And to that the answer is those “doors” are weaker because they are based on looser groupings, and part of that is because not all languages have the same alphabet. And the “by-name” structure does not lean into logical groupings that work better with this trail of thought because their correlation is low particularly by comparison to the SIG structure.
Well ideally users will have almost 0 interaction. More experienced users will hopefully know exactly what repos they will need. Otherwise they can all just use the top-level repo.
they don’t assuming any decent documentation. most of the time, a regular user making a home manager or nixos configuration will just want to pull in top-level similar to nixpkgs now
this is more aimed towards developers and power users. a good example here would be flakes not meant for end users, but to be consumed by other flakes (i.e., libraries such as pre-commit-hooks, flake-parts, snowfall, etc.). only pulling in core for example would help guarantee any api stability with aux/nixpkgs at a much lower cost compared to the current method of pulling in all of nixpkgs. likewise, individual packages from flakes could be used and binary caches could be taken advantage of without worrying about yet another 40mb+ nixpkgs tarball being downloaded just for it
space is a big one; i would this is an understatement, though. nixpkgs itself has gone from 30mb to 40mb within the last year or so, and seems to only be getting exponentially larger. this is turn forces users to be very careful about how many versions of nixpkgs end up in your flake, as even just two extra versions cause nixpkgs to take up 120mb+ alone. this is only going to get worse with time
also as isabel said, evaluation time is a concern. i experience issues with evaluating nearly anything on a fresh nixpkgs clone on the only macbook i have access to test darwin packages. smaller repos remedy this problem greatly. this is also not to mention full top level evaluations for tools like nixpkgs-review that can easily get killed by an oom daemon
Assuming we don’t drop top-level, then yeah, I think this makes sense to me. Most users would depend on top-level and just have everything ready to go for them, and anyone who really wants the modularity can bring in individual modules if they want. That sounds like an ideal situation to me.
Nixpkgs is a very high traffic repo. Lots of commits, lots of issues, lots of pull requests. The latter two especially are things that require triaging to ensure they get sent to the right team. And when your repo is as high traffic as Nixpkgs is, you’re inevitably going to miss some of it. This leads to issues and PRs getting lost amongst what is basically vast amount of noise to maintainers. Most issues and PRs are going to be ones that individual maintainers don’t care about - they’re mostly concerned with issues that affect the parts they maintain. Having the separate repos allows maintainers to break away from all their noise, and manage their own issue report log, their own PR queue, and their own committing/development process without having to worry about tripping over all the noise.
After reading over @getchoo proposal, I’m pretty convinced that a tiered approach would work better than a circular dependency mess.
My next question is, how do we want to organize packages within each SIG repos themselves? So far I’ve been testing out something similar to by-name such that packages are imported automatically based on directory placement, but also allowing for multiple package implementations. Any preferences? Prefer the by-name approach, grouped by category similarly to most of nixpkgs, or something else?
I think this is up to SIGs to answer for themselves - as long as flake outputs are standardized, I don’t see too much of an issue with SIGs deciding what the best layout for their requirements is.
My concern is that I don’t think circular dependencies are avoidable. There’s probably going to be quite a fair few repos in this setup, and I’m not convinced we can expect them all to fall out in a strictly acyclical dependency graph. I think this does represent an ideal structure though, and it’s something I’d be happy to base things off of, but I’d like to have a plan in place for what we do if/when we introduce a circle.
Yeah, sorry, I phrased it wrong, I meant how does importing the split repos help maintainers. I’m all for the split repos.
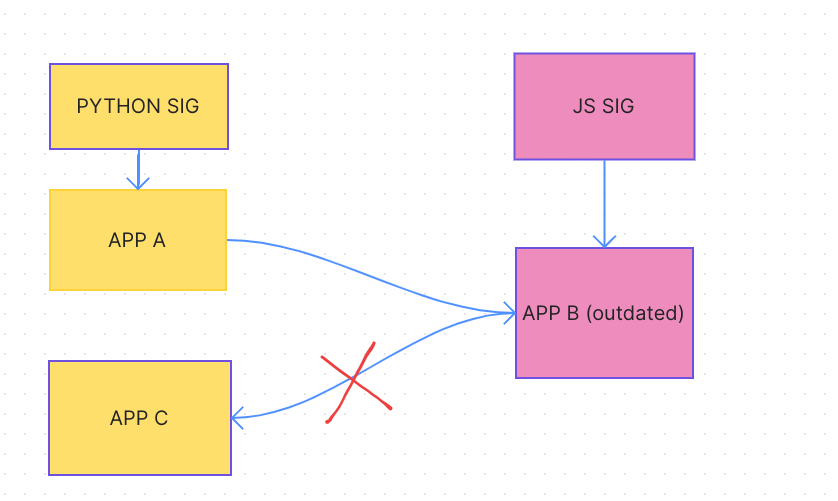
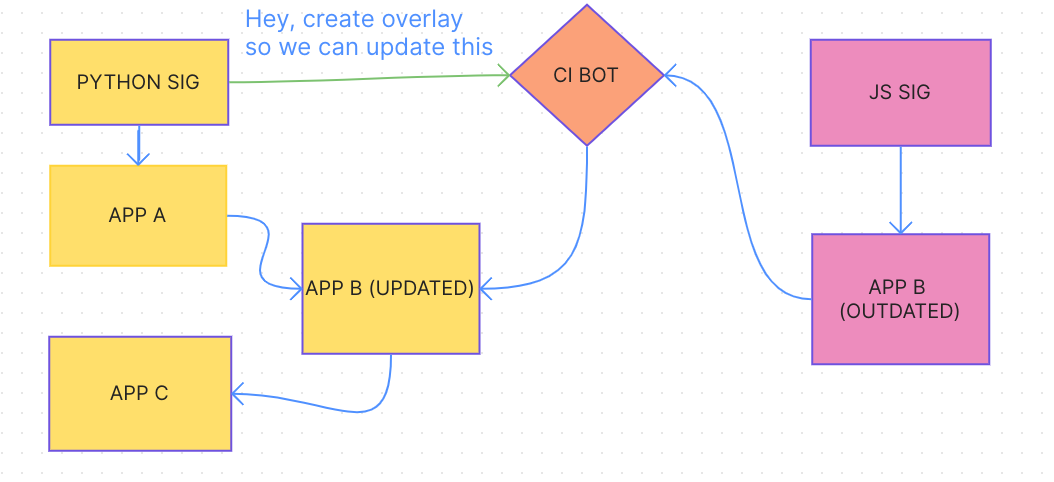
One thing that could happen is we could have overlays within each SIG and we have automation tools to backport it through to other SIGs.
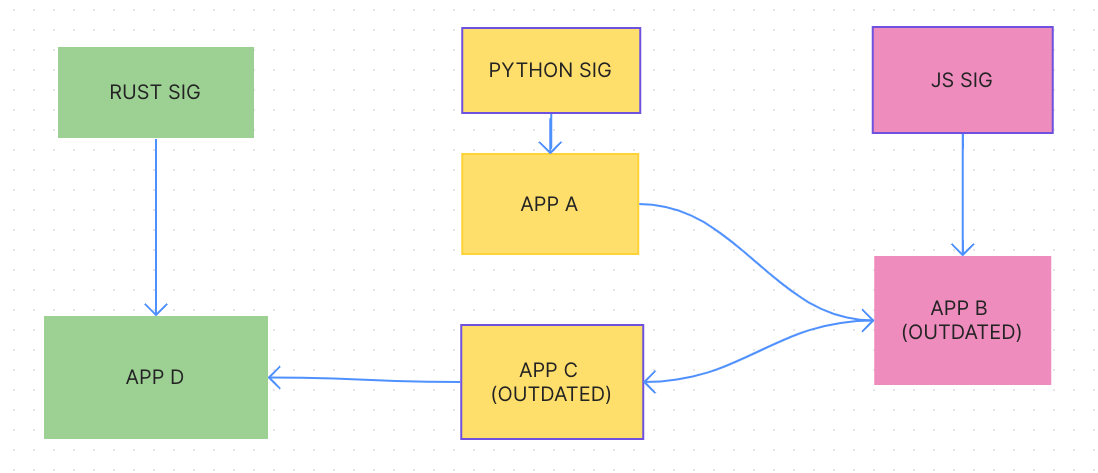
Python SIG has C but B is a blocker since it’s outdated, so it asks the CI bot to create an overlay. The overlay contains B’s derivation, but also metadata about where it came from. Python SIG updates it and pushes C no problem.
A couple issues I’m seeing already
Correct me if I’m wrong, but this solution is intended to resolve circular deps at the derivation level, right? I think this is too low a level for this structure - loops in derivation inputs necessitate a loop at the flake input level, and I think if the loop can be solved there, then we don’t really have issues at the derivation level. Overlays stop being a concern since each derivation only needs to worry about grabbing derivations from the flake input.
One really slow solution (if I’m understanding correctly) is to expose every package as a flake, and each input is itself a flake from a package from a different repo. This way, the top level of each SIG stays clear, and the loops are now all package (derivation) level. So you could still import the top level of a SIG which would pull packages from other sigs, but not have to pull everything and essentially create a monorepo. This would probably KILL eval time and storage though.
i think we should have some standard across each repo in order to ease onboarding contributors and helping with tree-wide code review
this is the most logical jumping off point to me. it has been proven extremely successful in nixpkgs, doesn’t arbitrary place many apps in overlay broad categories like “misc”, is easy for new contributors to understand, aids in navigation, and still keeps thing very organized. some wiggle room here (and other standards we set) should be available, though – after all some SIGs will probably have their own specific needs.
we already have a tool for this in core with lib.packagesFromDirectoryRecursive (thanks to @aemogie for introducing this to me a while ago!), which is fairly customizable and could provide that aforementioned wiggle room. if anyone wants to a see a basic example of this in the wild, you can here
just to get this out of the way, we should not be using overlays in anything to do with how end users will consume our flakes. this has many footguns which are explained in full detail here
the beginning of this example is also flawed. quoting myself from the aforementioned PR where i made my proposal:
this is assuming that a package re-used elsewhere is exclusive to a SIG/language-specific repo…which i don’t think should happen. core is currently described as “a common set of packages and tools used across Auxolotl,” which to me implies that package used across multiple repositories will be there (like node-gyp), not individual repos. if common packages are in a SIG/language-specific repo, something has gone wrong. i don’t believe there should be any situation where a javascript repo should depend on the entire python repo
for the record i would amend this now to say core and top-level would be used for projects that are (reverse) dependencies of multiple SIGs, but my point still stands: python should not depend on javascript and vice versa. (reverse) dependencies on anything besides core should be relegated to a higher (lower?) tiers in this tree like gnome/kde and top-level, or just core itself in order to block circular dependencies from happening in the first place – since as i think we’ve all seen by now, circular dependencies introduce massive complication and maintenance burden
I think I have a solution that will work:
Let’s say we have 4 repos: Core, A, B, and top-level. Their dependency graph looks like this, where an arrow pointing to a repo means “this repo is an input of the one it’s pointing to”:
Core
/ \
v v
A<-->B
\ /
v v
top-level
We make a change in Core, and need to propagate it to A, B, and top-level. We can safely do this with the following input definitions:
Repo A:
inputs = {
core.url = "github:auxolotl/core";
b = {
url = "github:auxolotl/b";
inputs.core.follows = "core";
};
}
Repo B:
inputs = {
core.url = "github:auxolotl/core";
a = {
url = "github:auxolotl/a";
inputs.core.follows = "core";
};
}
top-level:
inputs = {
core.url = "github:auxolotl/core";
a = {
url = "github:auxolotl/a";
inputs = {
core.follows = "core";
b.follows = "b";
};
};
b = {
url = "github:auxolotl/b";
inputs = {
core.follows = "core";
a.follows = "a";
};
};
}
With this, updates to core proceed as follows:
Now, Core is updated everywhere, and the updated version of Core is included in the dependencies of each repo, no matter which individual repo is being pulled - the follows definitions ensure Core remains in sync across all inputs.
Similarly, to update A:
Again, the follows definitions will ensure that the new version of A is propogated everywhere.
What about the case in which A is updated, B has the update merged, but top-level does not? In this case, pulling top-level will still include the old version of A everywhere, because top-level propogates A to all dependencies.
In short - for every input A in a given repo, A must have follows specified for every Auxolotl repo. In doing so, each repo is responsible for locking all other Auxolotl dependencies, and no one repo depends on another to keep shared dependencies in sync with each other.
One pitfall I see is repo B introducing a breaking change that breaks A, and top-level updating B - this would break A in top-level. I am currently rotating this situation in my head - I will report back if I find a solution.
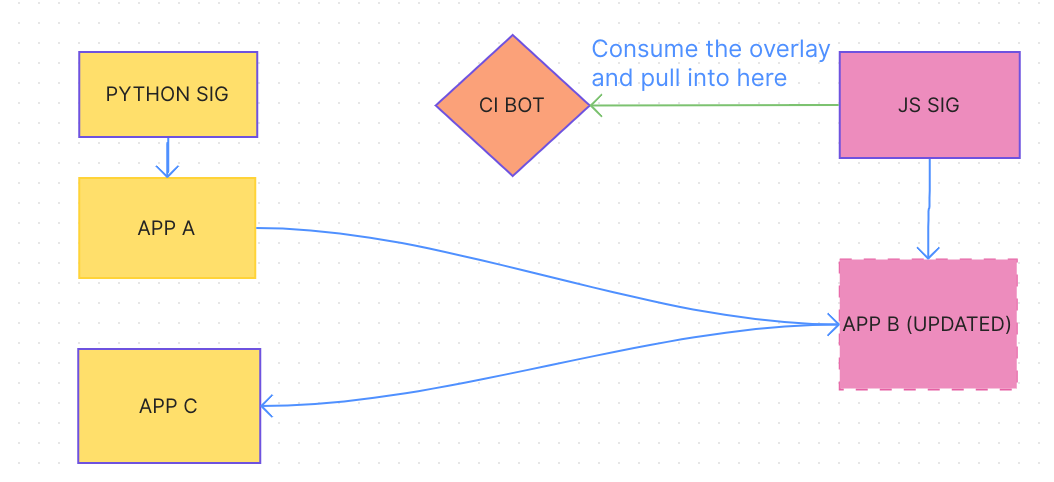
In my example, it would create an overlay of the derivation and copy it over, so you’re not importing a new version of the repo you’re copying from. In the example, python isn’t instantiating a new version of JS SIG, but overlaying the input to C with a local derivation that now resides in Python SIG. This would be then copied back over the JS SIG and deleted from python by the bot keeping track, so it wouldn’t have another input to JS SIG’s top level that wasn’t already imported in Python’s top level. Of course, this doesn’t solve the issue of flake import circles.
The issue with making sure that each SIG is “pure” is that it creates a ton of maintainer burden and slowly creeps towards a monorepo, no? For each combination we need to pass it off to a specific SIG (JS + Python SIG, JS + Python + Rust SIG), or we give it to top-level, which will increase in size as time goes on. And each SIG gets smaller and smaller as the dependency graph gets more hairy no? If not I’d appreciate more clarification, I admit I’m having a little trouble picturing the graph in my head.
LIke I said in my other response I’m having a little trouble envisioning the graphs (it’s 2am and I really should get some sleep but it is what it is), so bear with me. Isn’t this slower than the monorepo approach? I’m imagining we have A-E repos under core, and say we have a package in E that relies on D which relies on C which relies on … and so on. We need to wait for the A input to the flakes to update and propagate through builds, then the B, then the C, then the D, and so on — it could be a lot of flake input refresh cycles before something is available to be updated (also, if there’s circles, it could be a>b>c>b>c>d>e). So if the maintainers of E want to update their package, they need to wait for a, then b, then c, before they can finally get to looking at it, even before any potential troubleshooting the updates might bring. It could be overcome by updating inputs often, but at that point isn’t that just getting closer and closer to a monorepo that updates it’s “inputs” instantaneously?
I’m still of the mind that AuxPkgs should be a monorepo to end user and separate repos just for maintainers.
in general, this is reintroducing the problem of every package in A (let’s say python) depending on B (let’s say javascript) and vice versa. i’m not really understanding the focus on circular dependencies here, either. i genuinely do not see a case where it’s worth keeping repos independent, but then introducing huge dependency like all javascript packages for what would be (relatively) few python packages
the is in contrast to the tiered approach which makes sure our repositories for shared content (core and top-level) are for shared content, and language specific repositories are for language specific content. it also limits the many troubles we’re currently trying to work around with in regards to maintenance and dependencies outside of just core to lower/higher (i still haven’t decided on if core should considered the highest tier or top-level…so bear with me :p) tiers, where SIGs (like gnome and plasma) will be much smaller in comparison to the broad python/js/etc repositories. i think this gives them a very distinct opportunity to handle situations like this, as in general they will be much more specialized and not need to account for anything that could fall under the umbrella of a whole language
besides that, i don’t really see much in this message that explains how it would be a better solution than the proposal i made that vlinkz linked above – especially when you remove the assumption of circular dependencies being a requirement. i’m really reading this as a continuation of the original proposal more than anything
Hmm. I’m playing around with some ideas locally and it’s starting to become obvious to me that it’s very, very difficult to anticipate every permutation of outcomes here. I’m starting to think it might just be safest to go with the “tiered approach” for now, and try to address any problems as they come up. I think we will see problems - but the solutions to them will be much easier to find when we actually run into them, instead of simulating endless hypotheticals. Ideally, most of the problems will crop up during our bootstrapping phase, where we still have flexibility to make changes, and by the time everyone starts to stabilize out, we’ll have ironed out all the kinks.
It’s a play that doesn’t come without risks, but I think it’s the play we have to make if we want to move forward at this point.
Would you mind sharing what you have so far? I’d like to test some stuff locally too and would appreciate what you have as a jumping off point.
Here’s a gzipped tarball containing the repos I’ve been working with. Note the flake inputs are all absolute paths (to my knowledge, you can’t have relative paths as flake inputs) - you’ll need to change them to get them working on your system.